クエリファンアウト(Query Fan-out)とは?AI検索の仕組みとSEOへの影響を解説
更新日: 2026.06.04


近年、Google検索では生成AIを活用した回答機能が広がり、検索結果の見え方が大きく変わっています。その背景にあるのが、「クエリファンアウト(Query Fan-out)」と呼ばれる技術です。
クエリファンアウトとは、ユーザーの検索クエリを複数のサブクエリに分解し、それぞれを同時に検索して情報を集める仕組みを指します。これにより、AIは複数の情報源を横断して、より網羅的な回答を生成できるようになりました。
この変化は、ユーザーの検索体験だけでなく、SEOやコンテンツ制作にも影響を与えています。AI検索では、単にキーワードに一致するページではなく、複数の検索意図に対応した情報が引用されやすくなるためです。
この記事では、クエリファンアウトの仕組みをGoogle特許の内容も踏まえて整理し、AI検索での役割やSEOへの影響をわかりやすく解説します。
目次
クエリファンアウトとは何か
クエリファンアウトの定義
クエリファンアウト(Query Fan-out)とは、ユーザーが入力した検索クエリを複数のサブクエリに分解し、それぞれを並行して検索することで情報を収集する技術を指します。主に生成AIを活用した検索システムで利用されており、AIがより網羅的で精度の高い回答を生成するための重要な仕組みの一つです。
従来の検索エンジンでは、ユーザーが入力したキーワードをもとに関連性の高いWebページをランキング形式で表示することが中心でした。しかし、生成AIを活用した検索では、単にページを表示するだけでなく、複数の情報源を整理して回答として提示することが求められます。
こうした回答を実現するための情報収集技術が、クエリファンアウトです。具体的な仕組みは次のセクションで解説します。
検索クエリを分解して情報を取得する仕組み
クエリファンアウトの特徴は、ユーザーの質問をそのまま検索するのではなく、複数の小さな質問に分解して検索する点にあります。AIはユーザーの検索意図を分析し、回答を作るために必要な情報を複数のサブクエリとして生成します。
例えば、ユーザーが「クエリファンアウトとは?SEOへの影響は?」と検索した場合、AIは次のような複数のサブクエリを生成する可能性があります。
- クエリファンアウトの意味
- クエリファンアウトの仕組み
- AI検索との関係
- SEOへの影響
このように検索を分解して並列に実行することで、単一の検索では取得しきれない情報までカバーできるようになります。収集された情報は整理・統合され、ユーザーの質問に対する回答として提示されます。
従来の検索アルゴリズムとの違い
クエリファンアウトを理解するうえでは、従来の検索アルゴリズムとの違いを整理することが重要です。
従来の検索エンジンは、1つの検索クエリに対して関連性の高いWebページを抽出し、それらを順位付けして表示する仕組みでした。つまり、「どのページが最も適切か」を判断することが中心となります。
一方、クエリファンアウトを前提とした検索では、1つのクエリに対して複数の観点から情報を収集することが重視されます。そのため、単一のページとの一致度ではなく、回答に必要な情報をどれだけ多面的に集められるかが重要になります。
この違いにより、検索の役割は「最適なページを提示すること」から「回答に必要な情報を収集すること」へと広がっています。
| 項目 | 従来の検索 | クエリファンアウト |
|---|---|---|
| 検索の単位 | 1クエリ→1セットの結果 | 1クエリ→複数のサブクエリ |
| 情報取得の範囲 | 単一の検索結果 | 複数の観点から並列に取得 |
| 結果の形式 | ページの一覧表示 | 情報を統合した回答 |
| 評価の対象 | ページ単位の関連性 | パッセージ単位の情報価値 |
クエリファンアウトの処理プロセス

クエリファンアウトは、ユーザーの質問に含まれる意図を整理し、必要な情報を複数の観点から集め、一つの回答としてまとめる処理です。
ここでは「SEOツール おすすめ 比較」という検索例を使って、その流れを4つのステップに分けて解説します。
1. 検索クエリを意味単位に分解する
最初のステップは、ユーザーが入力した検索クエリを意味単位で読み解くことです。AIは「SEOツール おすすめ 比較」という検索語を、単なるキーワードの並びとしてではなく、複数の意図を含んだ質問として捉えます。
AIはこの検索に、少なくとも以下のような意図が含まれていると判断します。
- おすすめのツールを知りたい
- 複数の候補を比較したい
- 自分に合う選び方を知りたい
クエリファンアウトでは、まずこうした論点を整理し、どのような情報を集めるべきかの方針を立てます。
2. 論点ごとにサブクエリを生成する(Fan-out)
次に、整理した論点に応じてサブクエリを生成します。ここでは、元の検索語をそのまま分割するのではなく、情報を取得しやすい形に変換します。
例えばこのケースでは、AIは以下のようなサブクエリを生成します。
- SEOツール おすすめ
- SEOツール 比較
- SEOツール 選び方
- SEOツール 料金
AIはこうした複数の検索クエリを生成することで、一つの検索だけでは拾いきれない情報までカバーできるようになります。
3. サブクエリごとに検索を並列で実行する
生成されたサブクエリは、それぞれ独立した検索として並列に実行されます。これにより、AIは短時間で複数の情報源にアクセスし、異なる観点の情報を効率よく集めることができます。
例えば、ある検索では主要なSEOツールの一覧を取得し、別の検索では料金の比較情報を集め、さらに別の検索ではツール選定のポイントを確認するといった流れです。
並列に実行することで処理時間を抑え、ユーザーを待たせることなく多角的な情報収集を実現しています。
4. 集めた情報を統合して回答を生成する
最後に、複数の検索結果から得られた情報を整理し、一つの回答として再構成します。この段階では、内容の重複をまとめたり、比較しやすい順序に並べ替えたりしながら、ユーザーが理解しやすい形に整えられます。
この例であれば、AIは「代表的なSEOツール」「比較するときの主なポイント」「選ぶ際に確認したい項目」といった形で情報を整理し、全体像をつかみやすい回答の生成を試みます。その結果、ユーザーは複数のページを行き来しなくても、必要な判断材料をまとめて確認しやすくなります。
クエリファンアウトに関連するGoogle特許
Googleは公式に、AI OverviewやAI Modeではクエリファンアウトによって複数の関連検索をサブトピックやデータソースにまたがって実行すると説明しています。
AI による概要と AI モードは、「クエリ ファンアウト」手法を使う場合があります。
これは、関連する複数のサブトピックやデータソースに対して検索を実行し、それをもとに回答を組み立てる手法です。
引用:Google Search Central AI 機能とウェブサイト
ここでは、関連する特許をもとに、その背景となる技術を整理します。
多様な検索クエリを生成する考え方
Googleの特許(WO2024064249A1)では、多様な検索クエリを生成し、幅広い情報を取得するための考え方が示されています。
この特許の中心は、LLMを使って多様な検索クエリと文書の組み合わせ(合成トレーニングデータ)を生成し、文書検索モデルの学習に活用する仕組みにあります。つまり、検索モデルが多様な表現のクエリに対応できるよう、学習段階で幅広いクエリパターンを自動生成する技術です。
この考え方の背景には、クエリを単なるキーワードとして扱うのではなく、文脈や意図を考慮したうえで多様な表現に変換するという発想があります。例えば、同じ検索意図であっても「定義を知りたい」「仕組みを理解したい」「影響を把握したい」といった異なる角度からクエリが生成されることで、検索モデルがより幅広い問いかけに対応できるようになります。
このような処理によって、単一の検索では取得しきれない情報まで網羅的に収集できるようになります。これは、クエリファンアウトにおける「Fan-out(分解)」の工程に対応する技術といえます。
複数の情報を統合する仕組み(回答生成)
一方、別の特許(US20240289407A1)では、従来の検索セッションに生成AIを組み合わせた「ステートフルチャット」型の検索体験が説明されています。ユーザーのクエリに対して、文脈情報をもとに合成クエリ(synthetic queries)を生成し、それらの検索結果を活用して回答を生成するプロセスが示されています。
この技術では、各情報源の内容を単純に並べるのではなく、ユーザーのクエリや文脈情報、合成クエリ、検索結果をもとに状態データを管理し、それを活用して一貫性のある回答を生成することが重視されています。クエリの分類に基づいて適切な生成モデルを選択し、最適な回答を構成する仕組みです。
このプロセスは、クエリファンアウトにおける情報の統合・回答生成のフェーズに関連する技術といえます。複数の検索結果と文脈情報を組み合わせて、ユーザーにとって理解しやすい形で情報をまとめる役割を担っています。
特許からわかる検索の進化とSEOへの影響
これらの特許を整理すると、検索エンジンは単に関連ページを表示する仕組みから、複数の情報を収集・統合して回答を生成する仕組みへと進化していることが分かります。
重要なのは、このプロセスが「クエリ単位」ではなく「複数のサブクエリ単位」で情報収集されている点です。つまり、1つのキーワードだけに最適化されたコンテンツではなく、複数の検索意図に対応した情報が評価されやすくなっています。
この変化はSEOにも影響を与えています。今後は単一キーワードへの最適化だけでなく、関連するトピックや疑問を網羅的にカバーするコンテンツ設計がより重要になります。
クエリファンアウトと関連するAI技術
クエリファンアウトは単独の技術として存在しているわけではなく、生成AIや検索技術と組み合わさることで機能しています。特に重要なのが、LLM(大規模言語モデル)、RAG(検索拡張生成)、そしてナレッジグラフです。これらの技術が連携することで、検索クエリの分解から情報取得、回答生成までの一連の処理が実現されています。
LLM(大規模言語モデル)の役割
LLM(Large Language Model)は、自然言語を理解し、文章を生成するためのAIモデルです。Google検索では、自社開発のLLMであるGeminiがこの役割を担っており、AI OverviewsやAIモードの回答生成に活用されています。クエリファンアウトにおいては、主に「検索クエリの理解」と「回答生成」の2つの役割を果たしています。
まず、ユーザーが入力した検索クエリを解析し、その意図や文脈を理解する処理はLLMによって行われます。このとき、単なるキーワードではなく、文章全体の意味を踏まえて複数のサブクエリを生成します。
また、複数の検索結果から取得した情報をもとに、自然な文章として回答を生成するのもLLMの役割です。情報の整理や言い換え、文脈の統合などが行われることで、ユーザーにとって理解しやすい形に変換されます。
関連記事:LLMと生成AIの違いとは?定義や関係性を初心者向けに徹底解説
RAG(検索拡張生成)との関係
RAG(Retrieval-Augmented Generation)は、外部の情報を検索してから回答を生成する仕組みです。クエリファンアウトは、このRAGの「検索(Retrieval)」の部分を強化する役割を持っています。
通常のRAGでは、ユーザーのクエリをもとに関連する情報を検索し、それをもとに回答を生成します。クエリファンアウトは、この検索(Retrieval)の段階で機能し、単一のクエリではなく複数のサブクエリを並列に実行することで、より多くの関連情報を取得します。
これにより、より多角的な情報収集が行われ、回答の網羅性や精度が向上します。例えば、1つの質問に対して複数の観点から情報を取得できるため、より深い内容の回答が生成されるようになります。
つまり、クエリファンアウトはRAGの検索精度を高めるための仕組みとして機能しているといえます。
ナレッジグラフとの関係
ナレッジグラフは、情報同士の関係性を構造化して管理するデータベースの仕組みです。検索エンジンはこのナレッジグラフを活用することで、単語同士のつながりや意味的な関係を理解しています。
クエリファンアウトにおいては、サブクエリを生成する際にエンティティ間の関係性を参照したり、サブクエリの検索先としてナレッジグラフを活用したりしていると考えられています。
例えば、あるキーワードに関連するトピックや概念を把握することで、検索クエリをより適切に分解することが可能になります。また、異なる情報源の内容を結びつける際にも、ナレッジグラフが役立ちます。
クエリファンアウトによって検索結果はどう変わるか
クエリファンアウトの導入により、検索結果のあり方は大きく変化しています。
従来のようにWebページの一覧が表示されるだけでなく、AIが複数の情報を統合した「回答」として提示するケースが増えています。ここでは、具体的にどのような変化が起きているのかを整理します。
潜在的な検索意図まで考慮した回答生成
従来の検索では、ユーザーが入力したキーワードに直接対応する情報が中心に表示されていました。しかし、クエリファンアウトの導入により、明示されていない検索意図までカバーした回答が生成されるようになっています。
例えば、実際に「クエリファンアウトとは」と検索すると、以下のように表示されます。
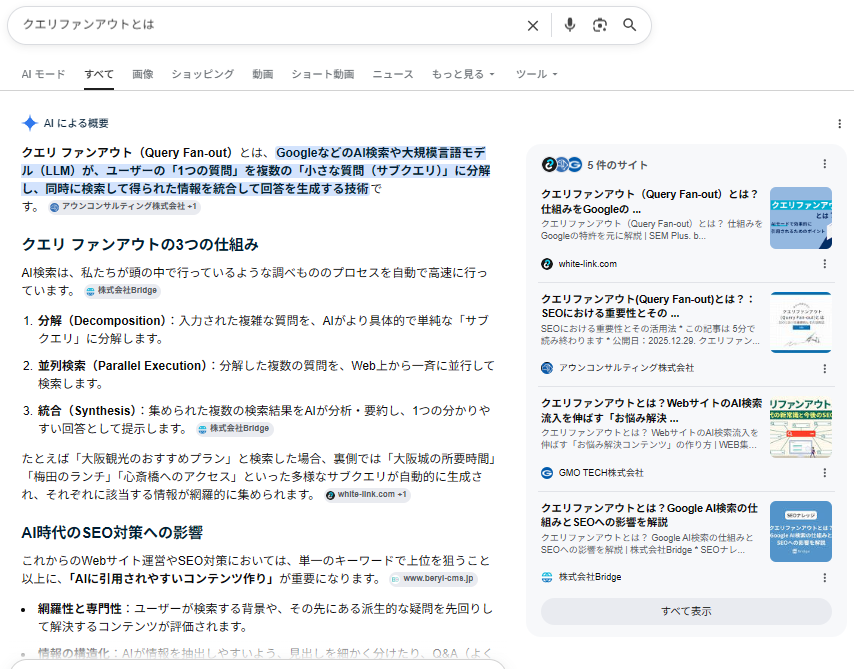
検索語には含めていない「仕組み」や「SEOへの影響」といった関連論点まで回答に含まれ、右側には参照元として複数のWebサイトが引用されています。これは、ユーザーが次に知りたくなる内容まで先回りして提示している状態といえます。
複数のサイトの情報を統合した回答
クエリファンアウトでは、複数のサブクエリをもとに検索が行われるため、異なるWebサイトから情報が収集されます。その結果、単一のサイトに依存しない、複数の情報源をもとにした回答が生成されます。
従来は、ユーザーが複数のページを開いて情報を比較する必要がありましたが、現在ではAIがそれらの作業を代わりに行い、整理された形で提示します。
この変化により、検索結果は「ページの集合」から「情報の統合結果」へとシフトしています。ユーザーはより短時間で全体像を把握できるようになりました。
比較・整理された情報が表示されやすくなる
クエリファンアウトによって複数の観点から情報が収集されるため、AIの回答には比較や整理された内容が含まれやすくなります。
例えば、あるテーマについて「メリット・デメリット」「違い」「ランキング」「選び方」といった形式の情報は、複数のサブクエリと相性が良く、AIに取り込まれやすい傾向があります。
実際に「SEOツール 選び方」のような比較を求めるクエリで検索すると、以下のように各ツールの特徴が並べて整理された回答が表示されます。単なる説明の羅列ではなく、判断材料として使いやすい構造で提示されている点が特徴です。
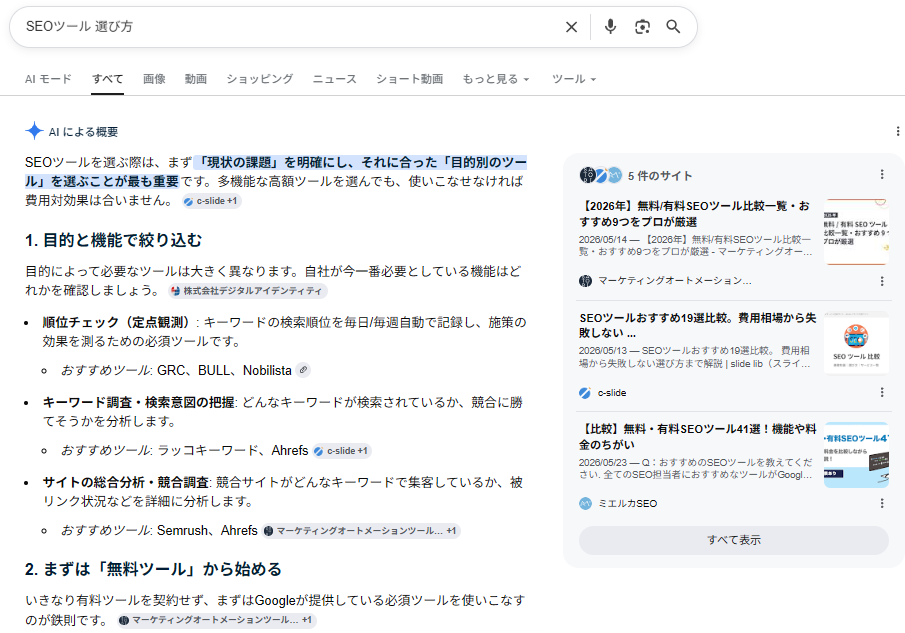
そのため、検索結果には単なる説明だけでなく、整理された情報や比較コンテンツが表示されるケースが増えています。
この変化は、コンテンツ制作にも影響を与えています。単なる情報の羅列ではなく、ユーザーにとって理解しやすい形で整理されたコンテンツが、より評価されやすくなっています。
クエリファンアウトがもたらす課題
クエリファンアウトは検索体験を大きく向上させる一方で、いくつかの課題も指摘されています。
複数のサブクエリをもとに情報を収集・統合する仕組みであるため、その過程で情報のズレや偏りが生じる可能性があります。ここでは、主な課題を整理します。
検索意図の誤解による回答のズレ
クエリファンアウトでは、サブクエリの生成精度が回答の質を左右します。この分解が適切でない場合、ユーザーの意図とは異なる方向で情報収集が行われる可能性があります。
例えば、ユーザーが特定の内容だけを知りたい場合でも、AIが広い意味で解釈してしまうと、不要な情報を含んだ回答が生成されることがあります。
このようなズレは、検索体験の質を低下させる要因となります。特に専門的な内容や文脈依存の強い検索では、意図の正確な理解が重要になります。
引用情報の偏り
クエリファンアウトは複数の情報源からデータを取得しますが、その選択はアルゴリズムに依存しています。そのため、特定の種類のコンテンツやサイトに偏る可能性があります。
例えば、AIはページ全体ではなくパッセージ(文章の断片)単位で情報を取得するため、要点が明確に整理されたコンテンツは取り込まれやすい一方で、文脈の中で意味を持つような詳細な解説は十分に反映されにくいケースも考えられます。
この結果、検索結果が特定の視点に偏るリスクがあります。
ランキング・比較情報の信頼性
クエリファンアウトによって、比較やランキング形式の情報が取り込まれやすくなっています。しかし、これらの情報は必ずしも客観的とは限りません。
特に、根拠が不明確なランキングや主観的な評価に基づく比較情報が引用されると、ユーザーに誤解を与える可能性があります。
AIが複数の情報を統合する際には、こうした情報の信頼性をどのように判断するかが重要な課題となります。
パーソナライズによる情報の偏り
AI検索では、ユーザーの検索履歴、位置情報、使用デバイスなどをもとに、生成されるサブクエリ自体がパーソナライズされる場合があります。これにより、ユーザーごとに異なる検索結果が表示されることがあります。
一方で、このパーソナライズは情報の偏りを生む要因にもなります。特定の傾向の情報ばかりが表示されることで、視野が狭くなる可能性があります。
このような現象は「フィルターバブル」とも呼ばれ、AI検索時代における重要な課題の一つとされています。
AI検索時代のコンテンツ戦略
クエリファンアウトの仕組みを踏まえると、従来のキーワード中心のSEO対策だけでは十分とはいえません。AIは複数のサブクエリをもとに情報を収集・統合するため、より広い検索意図に対応したコンテンツ設計が求められます。
ここでは、AI検索時代に重要となる具体的なコンテンツ戦略を解説します。
検索意図ベースのトピック設計
従来のSEOでは、特定のキーワードに最適化した記事を作成することが主流でした。
しかし、クエリファンアウトの仕組みでは複数の観点から情報が収集されるため、単一のキーワードだけを対象としたコンテンツでは情報が不足しやすくなります。
そのため重要になるのが、検索意図を起点としたトピック設計です。ユーザーが知りたい情報を起点に、「定義」「仕組み」「メリット」「活用方法」といった関連するテーマを一つの記事の中で網羅する必要があります。
具体的には、対策したいキーワードで実際に検索し、AI OverviewsやAIモードの回答に含まれている情報の観点を洗い出すことから始めてみてください。そこに含まれているテーマが、記事で扱うべきトピックの候補になります。
サブクエリを想定した記事構造
AIが複数の観点から情報を取得する以上、記事の構造もそれに対応させることが重要です。
具体的には、1つの大きなテーマに対して、ユーザーが抱くであろう疑問を見出しごとに分解し、それぞれが独立した問いと回答のセットになるように構成します。
例えば本記事であれば、
- クエリファンアウトとは(定義)
- 処理プロセス(仕組み)
- 関連するAI技術(技術的背景)
- SEOへの影響(実務への影響)
といったように、サブクエリ単位でセクションを分けています。
AIはページ全体ではなくパッセージ単位で情報を取得するため、1つのセクションが1つの問いに対応している構造のほうが、引用候補として選ばれやすい傾向があります。
まずは自社の既存記事の見出しを確認し、各見出しが独立した問いに対応しているかをチェックしてみてください。1つの見出しに複数の論点が混在している場合は、分割を検討する余地があります。
AIに引用されやすいコンテンツの書き方
記事の構造設計に加えて、各セクション内の書き方もAIの引用されやすさに影響します。以下のような特徴を持つコンテンツは、AIが情報を取得・引用しやすい傾向があると考えられます。
- セクションの冒頭で結論を述べている
- 具体的なデータや統計が含まれている
- 比較や分類が明確に整理されている
- 著者情報や一次情報など、信頼性(E-E-A-T)を示す要素が含まれている
- FAQ形式で見出しと回答が対応している
- 構造化データ(Schema Markup)でコンテンツの意味をAIに伝えている
- 定期的に更新されている
AIは複数の情報源からパッセージを取得し、回答を構成します。そのため、各セクションが独立して読める状態にしておくことが、AI検索時代のコンテンツにおいて重要なポイントです。
既存記事の改善から始める場合は、各セクションの冒頭文を確認し、そのセクションの結論が最初の1〜2文で述べられているかを見直すことが効果的です。
| 特徴 | 具体的なアクション |
| セクション冒頭で結論 | 各見出し直下の1〜2文で要点を述べる |
| データ・統計の活用 | 数値や調査結果を根拠として記載する |
| 比較・分類の整理 | メリット/デメリット、違いなどを明確に構造化する |
| 信頼性(E-E-A-T) | 著者情報、一次情報、専門性を示す要素を含める |
| FAQ形式の活用 | 見出しを疑問形にし、直下で簡潔に回答する構成にする |
| 構造化データの実装 | FAQPage、HowToなどのSchema Markupを実装し、AIにコンテンツの意味を伝える |
| 定期的な更新 | 情報の鮮度を保ち、更新日を明示する |
内部リンクとトピッククラスター
クエリファンアウトでは、1つのクエリに対して複数の関連トピックが検索されます。この性質に対応するためには、サイト全体でトピックを網羅する設計が重要です。
その際に有効なのが、トピッククラスターの考え方です。中心となる記事(ピラーコンテンツ)と、それを補完する複数の記事を内部リンクでつなぐことで、関連情報を体系的に整理できます。
これにより、検索エンジンに対してサイト全体のテーマ性を伝えやすくなり、AIにも理解されやすい構造になります。
結果として、個別の記事だけでなく、サイト全体の評価向上にもつながります。
対応の第一歩として、自社サイト内で同じテーマを扱っている記事同士が内部リンクでつながっているかを確認してみてください。関連記事が孤立している場合は、ピラーコンテンツを起点にリンク構造を整理することで、サイト全体のテーマ性が伝わりやすくなります。
関連記事:LLMOとは?SEOとの違いや生成AI時代に選ばれるサイトの対策を解説
センタードによるLLMO対策の支援事例
クエリファンアウトを前提としたコンテンツ設計は、実際の支援案件でも具体的な成果につながっています。ここでは、センタードがLLMO対策を支援したBtoBサービス事業者の事例を紹介します。
【事例】BtoBサービス事業者|AI回答からサブクエリを逆算する設計で、生成AI検索における引用獲得を実現
BtoBサービス事業者のお客様より、「生成AI検索での自社の露出状況を把握し、継続的に強化していきたい」とのご相談をいただきました。従来のSEO対策に加え、AI検索時代に対応したコンテンツ戦略の必要性を感じられている状況でした。
施策では、自社が引用されたい「想定プロンプト」を洗い出し、企業名が回答に登場しやすい「推薦を求めるタイプ」のプロンプトを優先しました。次に、想定プロンプトに対してAIが生成する回答を分析することで、AIがクエリファンアウトを通じて裏側で実行したサブクエリ群を逆算し、AIが評価していると考えられる情報需要を特定しました。この結果をもとに、既存ページの本文・メタ情報に、想定プロンプトの検索意図や取引先カテゴリなどを明示的に記載する改修を行いました。
その結果、生成AI検索における自社の引用獲得は競合を上回る水準で推移し、競合と並列で言及される場面でも安定して優位なポジションを確保しています。クエリファンアウトの仕組みを踏まえてサブクエリを逆算し、それに応えるコンテンツ設計を行うアプローチが、AI検索時代における引用獲得につながった事例となりました。
まとめ
クエリファンアウトとは、検索クエリをもとに複数の検索を同時に実行し、その結果を統合して回答を生成する仕組みです。生成AIを活用した検索の普及により、この技術は検索体験の中核として重要性を増しています。
現在では、AIが複数の情報源から情報を収集・統合し、回答として提示するようになっています。その裏側では、クエリの分解と情報の統合という処理が行われており、これが検索結果の質を大きく向上させています。
また、Googleの特許からも、こうした処理が実際の技術として設計されていることが確認できます。クエリファンアウトは単一の技術ではなく、複数の処理を組み合わせた仕組みとして理解することが重要です。
この変化はSEOにも大きな影響を与えています。単一キーワードに最適化するだけでなく、検索意図を軸にしたトピック設計や、サブクエリを意識したコンテンツ構造が求められるようになっています。
今後は、ユーザーの疑問に対して網羅的かつ整理された情報を提供できるかどうかが、検索評価を左右する重要なポイントとなります。クエリファンアウトの考え方を理解し、AI検索時代に適応したコンテンツ設計を行うことが、継続的な検索流入の確保につながります。
現在デジタルマーケティングにおいてお悩みがある方や、
課題を感じているがどうしていいかわからない方向けに
無料でご相談会を実施しております。
まずは自社の現状を知り、可能な改善施策はどういったものがあるのか、
スケジュール、予算感はどのようなものなのか等も含めて
ご説明しますので、お気軽にご相談ください。
監修者プロフィール

よくある質問
-
Q1クエリファンアウトとは簡単に言うと何ですか?
A.クエリファンアウトとは、ユーザーの検索クエリを複数のサブクエリに分解し、それぞれを同時に検索して情報を収集・統合する仕組みです。
一言でいうと、「AIがユーザーの代わりに複数の検索を行い、その結果をまとめて回答を生成する技術」といえます。これにより、ユーザーは複数回検索を行わなくても、必要な情報を一度に取得できるようになります。 -
Q2AI OverviewsやAIモードとの関係はありますか?
A.はい、どちらもクエリファンアウトを活用しています。
AI Overviewsは検索結果ページ上に表示されるAI生成の要約機能で、裏側ではクエリファンアウトによって複数の検索が実行され、情報を統合して回答が生成されています。
一方、AIモードはユーザーが切り替えて利用する対話型の検索機能で、より複雑な質問に対応するため、生成されるサブクエリの数も多くなり、クエリファンアウトの役割がより大きくなります。 -
Q3クエリファンアウトはSEOに影響しますか?
A.はい、影響します。クエリファンアウトでは複数のサブクエリをもとに情報が収集されるため、単一キーワードに最適化されたコンテンツだけでは十分に評価されない可能性があります。
関連記事:Googleの「AI Overview」とは?SGEとの違いやSEOへの影響、使い方を解説
そのため、SEOでは以下のような対応が重要になります。
・複数の検索意図をカバーする
・トピック単位でコンテンツを設計する
・見出しごとに明確な回答を用意する
このような対策を行うことで、AI検索にも対応したコンテンツを作成できます。 -
Q4AI検索時代に重要なコンテンツとは?
A.AI検索時代において重要なのは、「網羅性」と「構造化」です。ユーザーの疑問に対して、関連する情報を一つの記事の中で整理して提示することが求められます。
また、情報が分かりやすく整理されていることも重要です。見出しごとにテーマを明確にし、結論を簡潔に示すことで、AIにも理解されやすいコンテンツになります。
単なる情報量だけでなく、「どれだけ分かりやすく整理されているか」が評価のポイントになります。
-
セミナー
さらに学びたい方や、弊社のサービスについて知りたい方向けに通常セミナーや、時間を限定しないオンデマンドセミナーを用意しています。
開催セミナー一覧 -
資料ダウンロード
デジタルマーケティングに関するお役立ち資料や、弊社サービス資料をダウンロードいただけます。
資料ダウンロード一覧 -
サービスの
お問い合わせセンタードのサービスに関するご質問やお見積もり、ご発注など様々なお問い合わせはこちらからお気軽にお願いします。
お問い合わせフォーム

